The shift from symptomatic diagnosis to algorithmic prediction represents the most significant transition in oncology since the advent of genomic sequencing. In pancreatic ductal adenocarcinoma (PDAC), the diagnostic failure rate is tied to a biological latency period where tumors are visually undetectable but molecularly active. Current clinical protocols rely on late-stage indicators—jaundice, weight loss, or abdominal pain—at which point the five-year survival rate collapses to less than 10%. By reclassifying pancreatic cancer as a data-pattern problem rather than an imaging problem, deep learning models can identify high-risk trajectories up to three years before a physical mass manifests on a CT scan.
The Mathematical Barrier to Early Detection
The primary obstacle in PDAC screening is the low prevalence of the disease in the general population, which creates a "false positive paradox." Even an exceptionally accurate test will produce more false positives than true positives when the base rate of the disease is low. This leads to unnecessary, invasive biopsies and psychological trauma.
To bypass this, predictive models utilize Long Short-Term Memory (LSTM) networks and Transformer-based architectures to analyze Electronic Health Records (EHR) as a time-series. Instead of looking for a single biomarker, these systems identify a "composite signature" of subtle physiological shifts.
The Three Pillars of Algorithmic Predictive Power
The efficacy of AI in pre-symptomatic detection rests on its ability to synthesize three distinct data silos that human clinicians often view in isolation.
1. Longitudinal Metabolic Volatility
Standard clinical practice treats blood glucose levels as binary: diabetic or non-diabetic. AI analysis reveals that "new-onset diabetes" in patients over age 50 is often not Type 2 diabetes, but rather a paraneoplastic syndrome caused by the early-stage tumor. The algorithm detects specific rates of change ($d/dt$) in hemoglobin A1c and glucose levels that deviate from standard diabetic progression.
2. The Symptom Cluster Weighted Matrix
Individual symptoms like dyspepsia (indigestion) or back pain are statistically noisy and non-specific. However, AI assigns a weighted value to the temporal sequence of these events. A sequence of gallstones followed by a sudden prescription for proton pump inhibitors (PPIs) increases the risk score significantly more than either event occurring in isolation.
3. High-Dimensional Feature Extraction from EHR
Beyond structured data (lab results), Natural Language Processing (NLP) parses unstructured clinician notes. It identifies recurring mentions of "vague abdominal discomfort" or "unexplained fatigue" that, when mapped across millions of patient records, correlate with a 12-to-36-month precursor window for PDAC.
Structural Bottlenecks in Current Diagnostic Logic
The current diagnostic funnel is reactive, moving from general practitioner to specialist to imaging. This linear path is structurally incapable of catching early-stage lesions due to the following limitations:
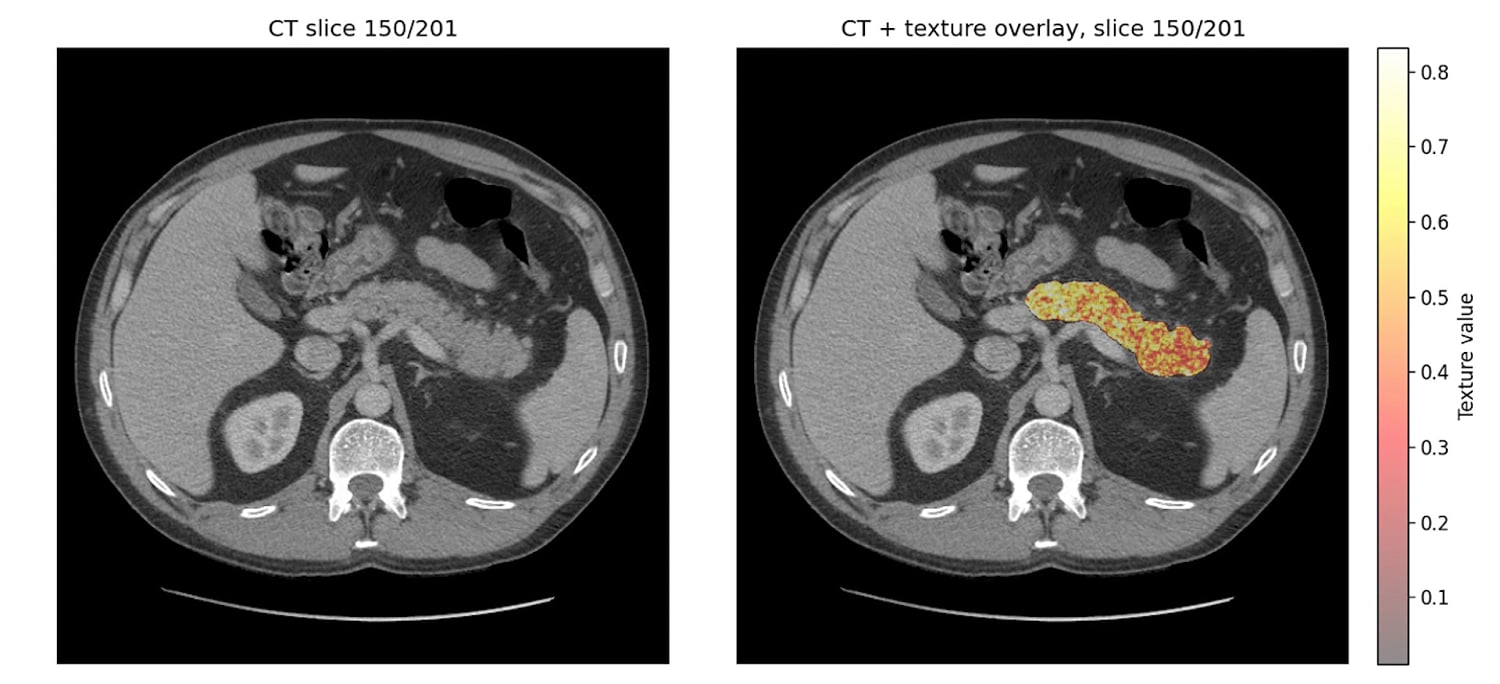
- Imaging Resolution Thresholds: Standard CT and MRI scans struggle to differentiate between chronic pancreatitis and early-stage T1 tumors. The "ground truth" for these models is often retrospective, training on scans that were originally labeled "clear" but contained subtle textural anomalies only visible to a machine.
- The Biomarker Specificity Gap: CA 19-9, the most common blood marker, is frequently elevated in non-cancerous conditions like biliary obstruction. AI reduces this noise by correlating CA 19-9 levels with secondary variables like liver function tests and age-adjusted baselines.
Quantifying the Predictive Horizon
Large-scale studies, including those utilizing data from the Danish National Patient Registry and the US Veterans Affairs system, demonstrate that AI can predict PDAC with an Area Under the Curve (AUC) of approximately 0.88 to 0.94 for a 12-month window.
This leads to a bifurcation of the patient population:
- Low-Risk General Population: Monitored through standard care.
- The High-Risk Cohort: Identified by AI for "Enriched Surveillance," utilizing endoscopic ultrasound (EUS) and multi-parametric MRI.
The goal is not to screen 300 million people, but to use data to narrow the "Search Space" by 90%, making intensive surveillance economically and clinically viable.
The Cost Function of Delayed Intervention
The economic argument for AI integration is as rigorous as the clinical one. A late-stage PDAC patient requires palliative care, multiple rounds of ineffective chemotherapy, and extended hospitalizations. Conversely, a patient diagnosed at Stage IA or IB is a candidate for the Whipple procedure (pancreaticoduodenectomy), which offers a significantly higher probability of long-term survival and reduced lifetime healthcare expenditures.
The "Cost of Discovery" via AI is essentially marginal, as it utilizes existing data infrastructures. The "Cost of Ignorance" is the systemic burden of treating a terminal disease that could have been resected if identified during the molecular latency phase.
Implementation Constraints and Data Biases
No algorithmic framework is without risk. Several factors limit the immediate, universal deployment of these systems:
- Data Heterogeneity: EHR systems across different hospital networks use different coding languages (ICD-10 vs. SNOMED). This creates "signal loss" when models trained on one population are applied to another.
- Overfitting on Comorbidities: There is a risk that models may become too sensitive to general markers of aging or obesity, leading to a higher false-positive rate in specific demographics.
- The Black Box Problem: Clinicians are often hesitant to order invasive tests based on an AI's "Black Box" recommendation without a clear physiological explanation. Explainable AI (XAI) modules are required to highlight which specific data points triggered the high-risk score.
Strategic Realignment of Clinical Workflow
To operationalize these findings, healthcare systems must move away from the "One-Time Test" mentality toward "Continuous Risk Profiling."
The strategic play involves integrating AI directly into the EHR backend. When a patient’s data trajectory enters the high-risk decile, an automated flag is sent to the primary care physician, recommending a specific diagnostic pathway. This shifts the burden of vigilance from the human doctor—who cannot possibly memorize the longitudinal patterns of thousands of patients—to a persistent, algorithmic monitor.
The focus must remain on the T1a and T1b stages. If the AI identifies a patient at Stage IV, it has failed its primary objective. The value lies entirely in the delta between the algorithmic alert and the first physical symptom. Success is measured not by the complexity of the neural network, but by the number of months it shaves off the diagnostic timeline, moving the needle from palliative care to surgical cure.
Health systems should prioritize the deployment of these models within "High-Incidence Subgroups," specifically new-onset diabetics and patients with a family history of gastrointestinal malignancies. By focusing the algorithm's power on these pre-filtered groups, the "False Positive Paradox" is mitigated, and the positive predictive value (PPV) is maximized. This targeted application is the only viable path toward a sustainable, AI-driven screening program for pancreatic cancer.